2026
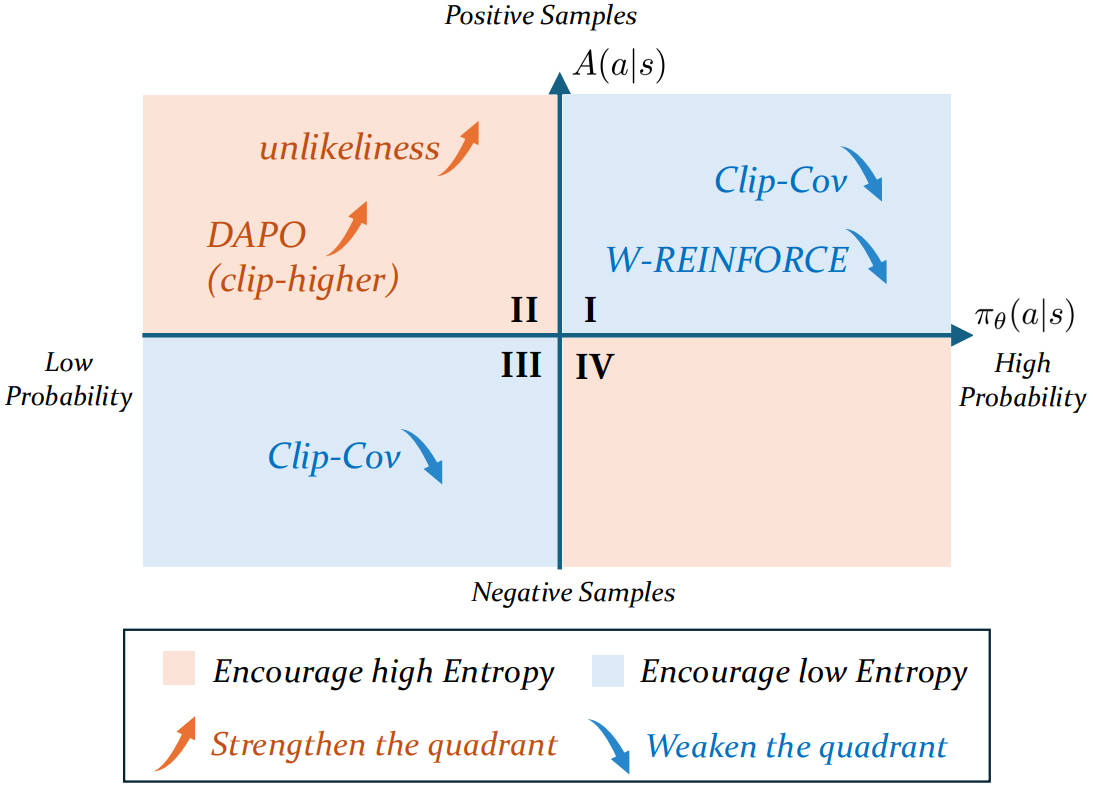
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, Jiawei Chen
Annual Meeting of the Association for Computational Linguistics (ACL) 2026
We propose a quantitative analysis framework for entropy change. Building on this, the effect of entropy interventions can be unified and elucidated through token-level analysis. Our findings point out a fundamental limitation of existing methods: they attempt to control the entropy indirectly. By only affecting related factors, such as the advantage signal and generation probability, their effectiveness is inherently limited and could potentially fail.
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, Jiawei Chen
Annual Meeting of the Association for Computational Linguistics (ACL) 2026
We propose a quantitative analysis framework for entropy change. Building on this, the effect of entropy interventions can be unified and elucidated through token-level analysis. Our findings point out a fundamental limitation of existing methods: they attempt to control the entropy indirectly. By only affecting related factors, such as the advantage signal and generation probability, their effectiveness is inherently limited and could potentially fail.
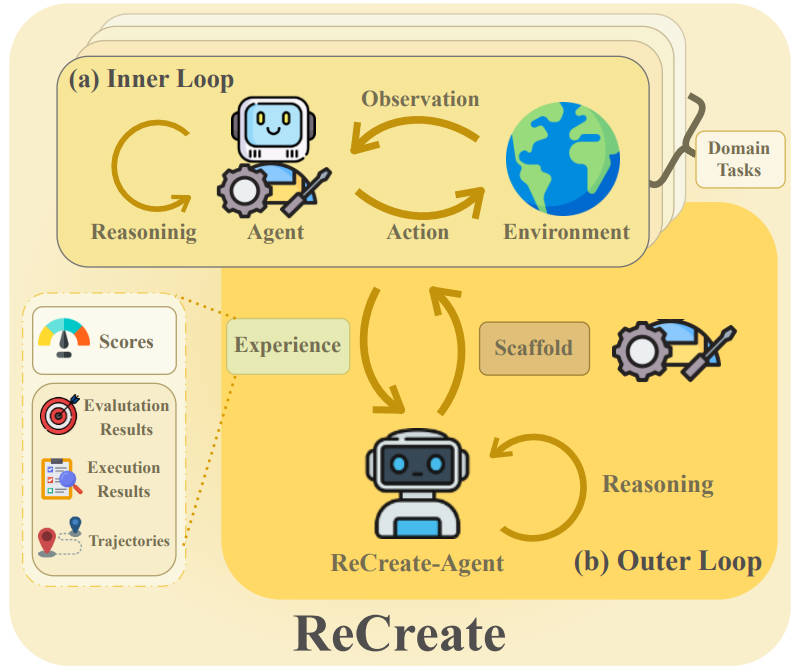
ReCreate: An Experience-Driven Framework for the Automatic Creation of Domain Agents
Zhezheng Hao, Hong Wang, Jian Luo, Jiaqing Zhang, Yuyan Zhou, Qiang Lin, Can Wang, Hande Dong, Jiawei Chen
Annual Meeting of the Association for Computational Linguistics (ACL) 2026
We propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
ReCreate: An Experience-Driven Framework for the Automatic Creation of Domain Agents
Zhezheng Hao, Hong Wang, Jian Luo, Jiaqing Zhang, Yuyan Zhou, Qiang Lin, Can Wang, Hande Dong, Jiawei Chen
Annual Meeting of the Association for Computational Linguistics (ACL) 2026
We propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
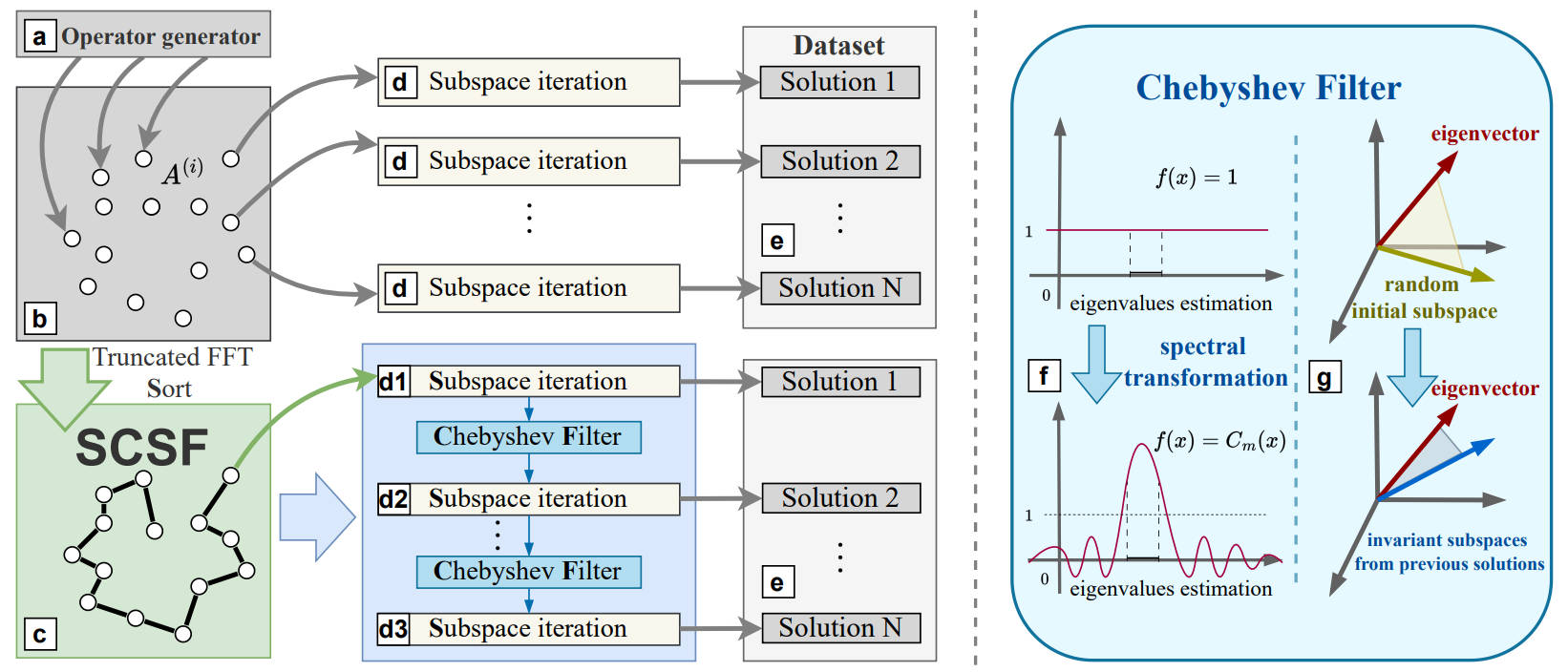
Accelerating Eigenvalue Dataset Generation via Chebyshev Subspace Filter
Hong Wang, Jie Wang, Jian Luo, Huanshuo Dong, Yeqiu Chen, Runmin Jiang, Zhen Huang
International Conference on Learning and Representations (ICLR) 2026
we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators—a factor overlooked by existing methods. SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations.
Accelerating Eigenvalue Dataset Generation via Chebyshev Subspace Filter
Hong Wang, Jie Wang, Jian Luo, Huanshuo Dong, Yeqiu Chen, Runmin Jiang, Zhen Huang
International Conference on Learning and Representations (ICLR) 2026
we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators—a factor overlooked by existing methods. SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations.
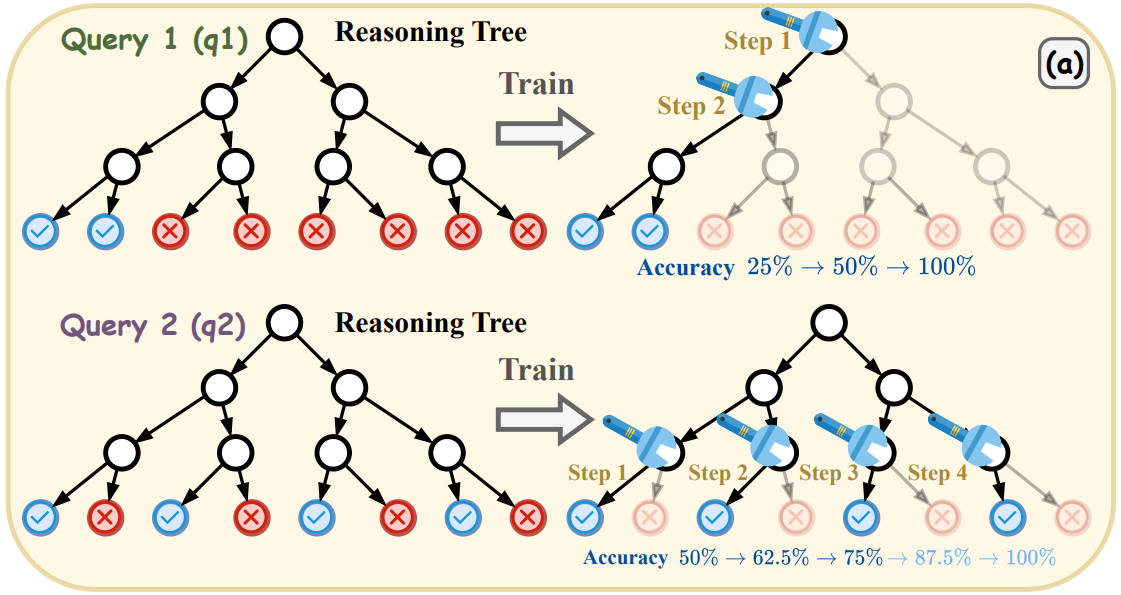
Scheduling Your LLM Reinforcement Learning with Reasoning Trees
Hong Wang, Zhezheng Hao, Jian Luo, Chenxing Wei, Yao Shu, Lei Liu, Qiang Lin, Hande Dong, Jiawei Chen
International Conference on Learning and Representations (ICLR) 2026
In this paper, we introduce a novel metric, namely Reasoning Score (r-score), which measures the query’s learning difficulty based on the structure of its reasoning tree. Based on the r-score, we propose the Reasoning Tree Schedule (ReSchedule), a scheduling algorithm that constructs a curriculum progressing from structurally simple (high r-score) to complex (low r-score) queries. Experiments on six math-reasoning benchmarks show that Re-Schedule significantly improves average accuracy, achieving gains of up to 3.2%.
Scheduling Your LLM Reinforcement Learning with Reasoning Trees
Hong Wang, Zhezheng Hao, Jian Luo, Chenxing Wei, Yao Shu, Lei Liu, Qiang Lin, Hande Dong, Jiawei Chen
International Conference on Learning and Representations (ICLR) 2026
In this paper, we introduce a novel metric, namely Reasoning Score (r-score), which measures the query’s learning difficulty based on the structure of its reasoning tree. Based on the r-score, we propose the Reasoning Tree Schedule (ReSchedule), a scheduling algorithm that constructs a curriculum progressing from structurally simple (high r-score) to complex (low r-score) queries. Experiments on six math-reasoning benchmarks show that Re-Schedule significantly improves average accuracy, achieving gains of up to 3.2%.
2025
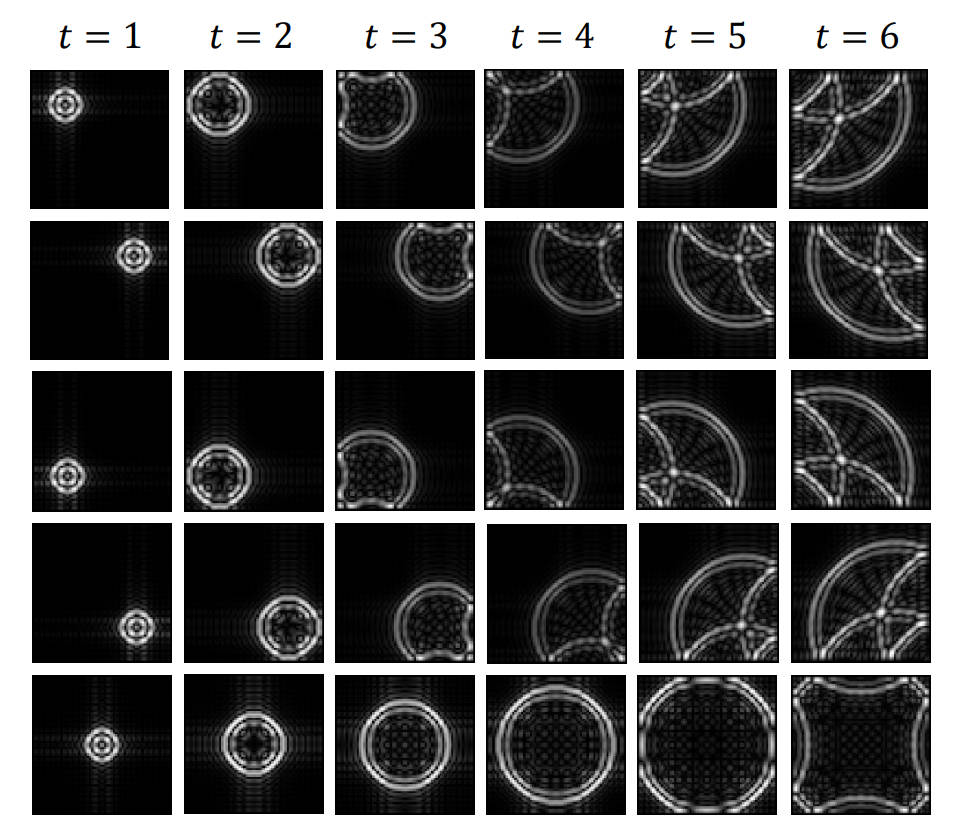
Can Data-Driven Dynamics Reveal Hidden Physics? There Is A Need for Interpretable Neural Operators
Wenhan Gao*, Jian Luo*, Fang Wan, Ruichen Xu, Xiang Liu, Haipeng Xing, Yi Liu (* equal contribution)
Under review. 2025
We provide a way to explain the prediction-making process of neural operators and show that neural operator can learn hidden physical patterns from data. However, this explanation method is limited to specific situations, highlighting the urgent need for generalizable explanation methods. Next, we show that a simple dual-space multi-scale model can achieve SOTA performance and we believe that dual-space multi-spatio-scale models hold significant potential to learn complex physics and require further investigation. Lastly, we discuss the critical need for principled frameworks to incorporate known physics into neural operators, enabling better generalization and uncovering more hidden physical phenomena.
Can Data-Driven Dynamics Reveal Hidden Physics? There Is A Need for Interpretable Neural Operators
Wenhan Gao*, Jian Luo*, Fang Wan, Ruichen Xu, Xiang Liu, Haipeng Xing, Yi Liu (* equal contribution)
Under review. 2025
We provide a way to explain the prediction-making process of neural operators and show that neural operator can learn hidden physical patterns from data. However, this explanation method is limited to specific situations, highlighting the urgent need for generalizable explanation methods. Next, we show that a simple dual-space multi-scale model can achieve SOTA performance and we believe that dual-space multi-spatio-scale models hold significant potential to learn complex physics and require further investigation. Lastly, we discuss the critical need for principled frameworks to incorporate known physics into neural operators, enabling better generalization and uncovering more hidden physical phenomena.
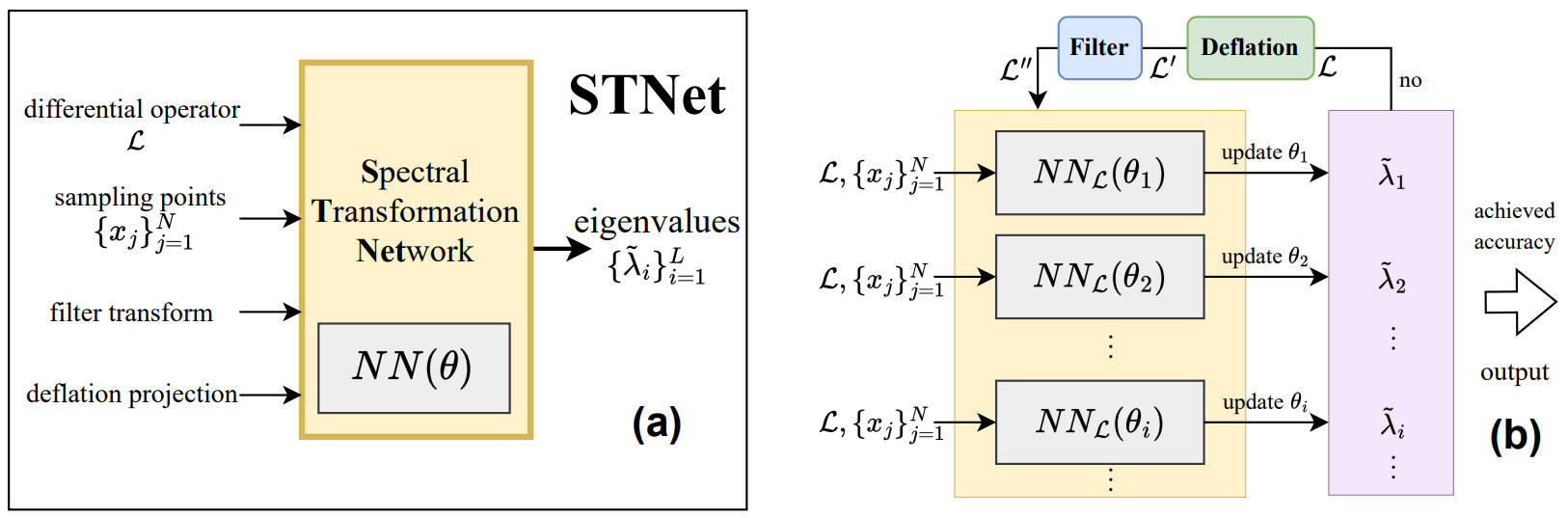
STNet: Spectral Transformation Network for Solving Operator Eigenvalue Problem
Hong Wang*, Yixuan Jiang*, Jie Wang, Xinyi Li, Jian Luo, Huanshuo Dong (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2025
we propose the Spectral Transformation Network (STNet). During each iteration, STNet uses approximate eigenvalues and eigenfunctions to perform spectral transformations on the original operator, turning it into an equivalent but easier problem.
STNet: Spectral Transformation Network for Solving Operator Eigenvalue Problem
Hong Wang*, Yixuan Jiang*, Jie Wang, Xinyi Li, Jian Luo, Huanshuo Dong (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2025
we propose the Spectral Transformation Network (STNet). During each iteration, STNet uses approximate eigenvalues and eigenfunctions to perform spectral transformations on the original operator, turning it into an equivalent but easier problem.
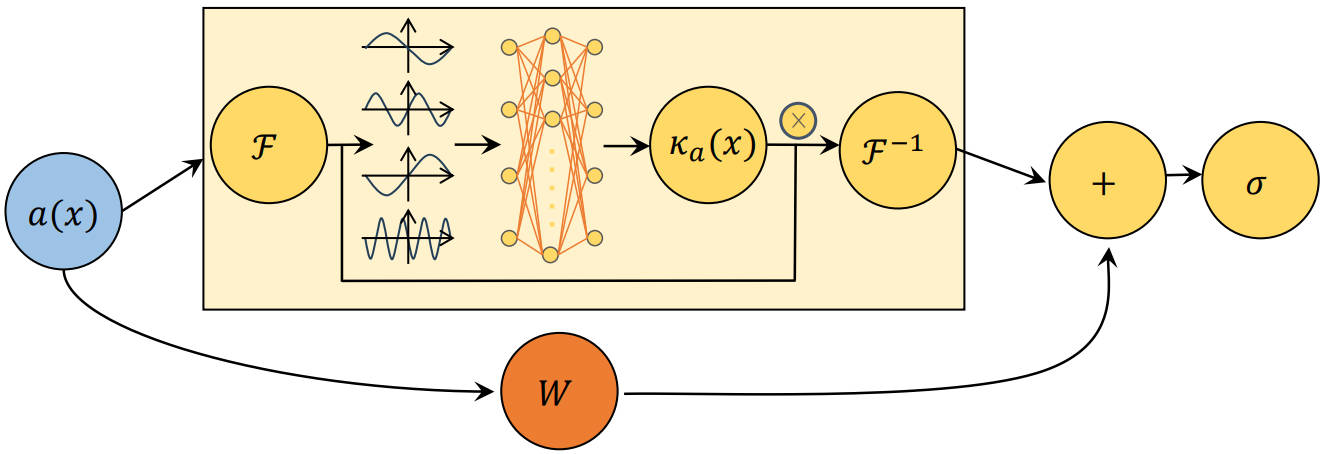
Dynamic Schwartz-Fourier Neural Operator for Enhanced Expressive Power
Wenhan Gao, Jian Luo, Ruichen Xu, Yi Liu
Transactions on Machine Learning Research (TMLR) 2025
we introduce a novel approach that equips FNOs with Schwartz operatorsto learn dynamic kernels, termed Dynamic Kernel Fourier Neural Operators (DSFNOs). By incorporating this dynamic mechanism, our model gains the ability to capture relevant frequency information patterns, facilitating a better understanding and representation of complex physical phenomena.
Dynamic Schwartz-Fourier Neural Operator for Enhanced Expressive Power
Wenhan Gao, Jian Luo, Ruichen Xu, Yi Liu
Transactions on Machine Learning Research (TMLR) 2025
we introduce a novel approach that equips FNOs with Schwartz operatorsto learn dynamic kernels, termed Dynamic Kernel Fourier Neural Operators (DSFNOs). By incorporating this dynamic mechanism, our model gains the ability to capture relevant frequency information patterns, facilitating a better understanding and representation of complex physical phenomena.
2024
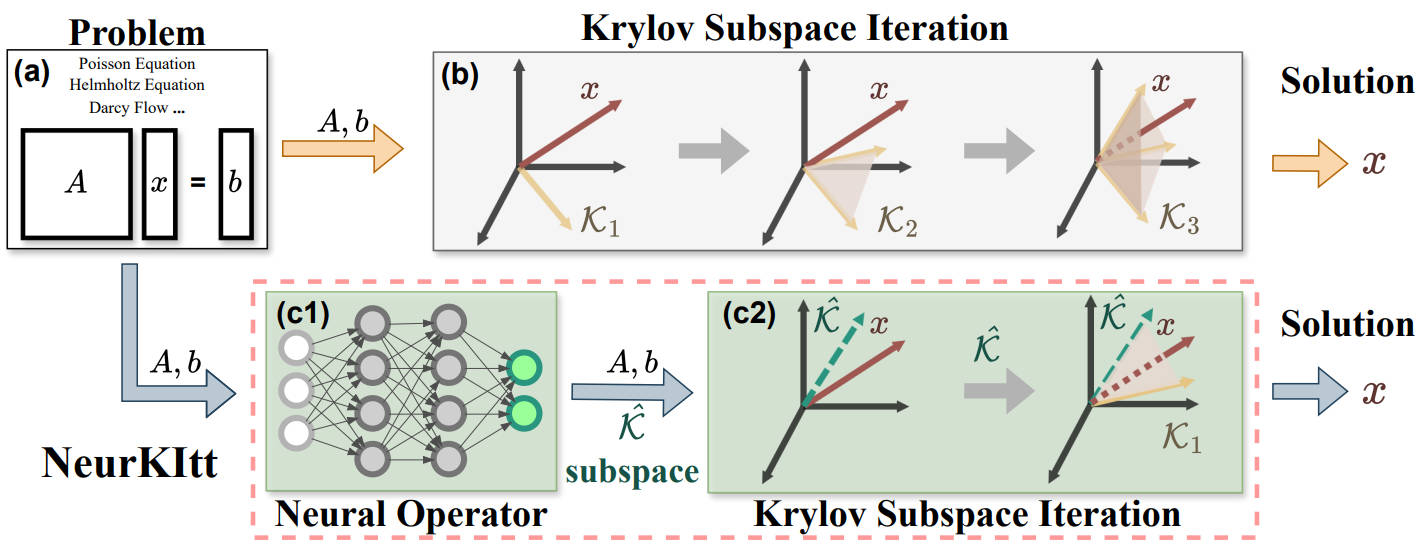
Neural Krylov Iteration for Accelerating Linear System Solving
Jian Luo, Jie Wang, Hong Wang, Huanshuo Dong, Zijie Geng, Hanzhu Chen, Yufei Kuang
Advances in Neural Information Processing Systems (NeurIPS) 2024 Spotlight
We propose a novel method, namely Neural Krylov Iteration (NeurKItt), for accelerating linear system solving. To enhance the subspace prediction accuracy, we utilize QR decomposition for the neural operator outputs and introduce a novel projection loss function for training. NeurKItt accelerates the solving of linear systems across various settings and datasets, achieving up to a 5.5× speedup in computation time and a 16.1× speedup in the number of iterations.
Neural Krylov Iteration for Accelerating Linear System Solving
Jian Luo, Jie Wang, Hong Wang, Huanshuo Dong, Zijie Geng, Hanzhu Chen, Yufei Kuang
Advances in Neural Information Processing Systems (NeurIPS) 2024 Spotlight
We propose a novel method, namely Neural Krylov Iteration (NeurKItt), for accelerating linear system solving. To enhance the subspace prediction accuracy, we utilize QR decomposition for the neural operator outputs and introduce a novel projection loss function for training. NeurKItt accelerates the solving of linear systems across various settings and datasets, achieving up to a 5.5× speedup in computation time and a 16.1× speedup in the number of iterations.
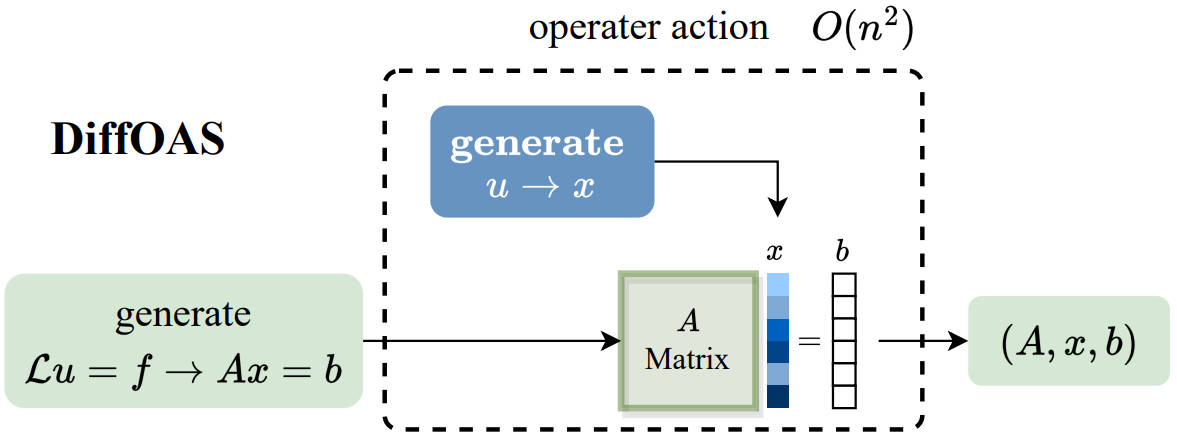
Accelerating PDE Data Generation via Differential Operator Action in Solution Space
Huangshuo Dong, Hong Wang, Haoyang Liu, Jian Luo, Jie Wang
International COnference on Machine Learning (ICML) 2024
we propose a novel PDE dataset generation algorithm, namely Differential Operator Action in Solution space (DiffOAS), which speeds up the data generation process and enhances the precision of the generated data simultaneously. DiffOAS obtains a few basic PDE solutions and then combines them to get solutions. It applies differential operators on these solutions, a process we call ’operator action’, to efficiently generate precise PDE data points. Even with just 5% of the generation time, NO trained on the data generated by DiffOAS exhibits comparable performance to that using the existing generation method, which highlights the efficiency of DiffOAS.
Accelerating PDE Data Generation via Differential Operator Action in Solution Space
Huangshuo Dong, Hong Wang, Haoyang Liu, Jian Luo, Jie Wang
International COnference on Machine Learning (ICML) 2024
we propose a novel PDE dataset generation algorithm, namely Differential Operator Action in Solution space (DiffOAS), which speeds up the data generation process and enhances the precision of the generated data simultaneously. DiffOAS obtains a few basic PDE solutions and then combines them to get solutions. It applies differential operators on these solutions, a process we call ’operator action’, to efficiently generate precise PDE data points. Even with just 5% of the generation time, NO trained on the data generated by DiffOAS exhibits comparable performance to that using the existing generation method, which highlights the efficiency of DiffOAS.